Linux kernel 启动流程
Linux kernel 启动流程
前置知识
MBR 分区和GPT 分区
MBR (Master Boot Record)分区
MBR指的是指定开机指定启动硬盘的第一个扇区,通常为512字节,为什么说分区方法也叫MBR呢,因为这个扇区包括了两部分内容: bootstrap code area和partition table
- bootstrap code area占据446个字节,包含了启动相关的代码
- partition table分区表占据了64个字节,包含了四个分区表的内容,每个分区表占据16个字节,MBR每个分区表占据16个字节,比如:
80 01 01 00 0B FE BF FC 3F 00 00 00 7E 86 BB 00
| 字节内容 | 长度 | 含义 |
| --- | --- | --- |
| **`80`** | 1 字节 | 分区状态:`00` 非活动分区,`80` 活动分区 |
| **`01 01 00`** | 3 字节 | 表示分区起始的 `C/H/S`(但不指C=1, H=1, S=0) |
| **`0B`** | 1 字节 | 文件系统标志位:"`0B`"表示分区的系统类型是`FAT32`,其他常用的有`04(FAT16), 07(NTFS)` |
| **`FE BF FC`** | 3 字节 | 共同表示分区结束的 `C/H/S` |
| **`3F 00 00 00`** | 4 字节 | 分区起始相对扇区号 |
| **`7E 86 BB 00`** | 4 字节 | 分区总的扇区数 |
446+64 = 510,还剩下最后两个字节的内容为0x55aa,这是MBR的标志所以MBR这个名词不仅仅指磁盘的第一个扇区,它还暗指了上面的这种布局以及分区格式
- 由于MBR格式的分区表只能识别四个分区(这些分区叫主分区),如果想分四个以上的分区,必须创建一个分区,该分区用于存放更多的分区表,这样的分区叫做扩展分区,扩展分区只能有一个: 分区方式为4个主分区或者3个主分区加上一个扩展分区。
- 由于MBR使用4个字节表示分区总的扇区数,因此它可以表示的最大分区大小为
2199023255552字节,约为2T,这也是MBR的一个限制。
GPT(GUID Partition Table)分区
GPT采用LBA的地址格式,为了向后兼容以及用来防止不支持GPT的硬盘管理工具错误识别并破坏硬盘中的数据,LBA0仍然给MBR使用,不过MBR里边只有一块分区,分区类型为0xEE,这种MBR又叫"Protective MBR"。
GPT的格式维基百科中有详细描述,它还有一块区域用来备份分区表,在磁盘的末尾部分:
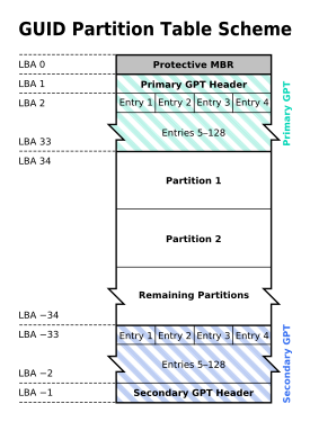
按照GPT的格式,磁盘真正的分区数据部分从LBA34开始,但分区软件一般将GPT分区边界对齐,比如对齐到2048扇区处:1048576 Byte,所以一般分区的数据从LBA2048开始,因此从LBA34到LBA2048有一块大约1MB的间隙。
Pixel 6 Pro 手机的 sd 设备如下:
1 | raven:/sys/block $ ls -l sd* |
可以看到有多个sd设备,但是这并不是代表有六个物理设备,而是把一个ufs物理设备分成四块,称之为LU(Logical Unit),它们的逻辑地址空间是独立的,都是从LBA 0开始,因此都有各自的分区表结构。
比如sda的分区表,其LBA大小为4096字节,按照上面的GPT分区格式:
- LBA0是
Protect MBR - LBA1是分区表头,
Primary GPT Header - LBA2-LBA33是分区表,系统相关的分区例如
system_a、system_b、boot、vendor、data等,都是安卓操作系统用来存储不同功能和数据的分区。system_a和system_b是为了支持A/B分区更新机制,常见于安卓8及以后的版本,其中system_a和system_b分别代表两个独立的系统分区,可以在不同版本的系统之间进行切换。bootloader会根据分区表来知道需要刷写的具体分区。
- A/B 分区是为了支持无缝更新(Seamless Updates)机制的设计,常见于 Android 8 及以上版本。系统分为两个独立的区域,分别是
system_a和system_b,它们是两个独立的系统分区。system_a存放当前活跃的系统(通常是正在运行的版本),system_b存放备用系统(通常是更新后的版本)。当更新时,系统会将新版本的系统安装到system_b,并在下次启动时切换到该分区。这允许设备在升级时避免系统挂起,并提供一个可靠的回滚机制。 - Bootloader负责管理设备的引导过程,包括刷写系统分区、恢复操作等。当执行类似
fastboot flash system_a system.img这样的命令时,Bootloader会解析设备的分区表(通常是GPT),确定系统镜像要写入哪个分区(比如system_a)。 - Linux内核在启动时会扫描所有的块设备(block devices),并生成相应的gendisk数据结构,用于描述设备上的分区。以高通UFS设备为例,内核会通过一系列函数(如
sd_probe)扫描和识别设备上的每个逻辑单元(LU)。 - 内核将设备和分区信息通过 sysfs 公开,
/sys/block/sda这样的路径表示块设备的元数据。分区信息会在每个设备的子目录中创建,如/sys/block/sda/sda1,/sys/block/sda/sda2等,表示/dev/sda上不同的分区。这些目录通过kobject机制(一个内核对象系统)来管理,允许内核和用户空间通过sysfs接口访问块设备和分区。 - 内核会触发
uevent事件,init进程会响应这些事件,在/dev目录下创建对应的块设备文件。例如,/dev/block/sda表示整个sda设备,/dev/block/sda1、/dev/block/sda2等表示各个分区。 - 通过
sysfs,内核暴露分区信息,用户空间通过/dev进行访问,同时设备名称和分区名称的映射通过符号链接体现。
ramdisk, initrd, ramfs, tmpfs, initramfs, rootfs, 根文件系统
ramdisk:ramdisk简单来说就是RAM模拟为硬盘的技术。当ramdisk功能开启以后会有如下的设备文件:/dev/ram0,/dev/ram1,/dev/ram2 ... /dev/ram15,由于每一块模拟的都是硬盘,因此可以直接格式化为指定文件系统并挂载。- 根文件系统:这里指的linux系统启动以后最终/目录所在的那个文件系统。
ramfs, tmpfs, rootfs:都是文件系统,因为ramdisk有着一些缺点,Linus Torvalds创建出了ramfs文件系统,它将linux的缓存机制(page cache和dentry cache)用做动态的可扩展的基于ram的文件系统。在ramfs的基础上其他内核开发者又创建了一个改善版本叫做tmpfs,tmpfs可以将数据写入交换分区,并且可以限制挂载点的大小。rootfs虽然它直译过来是”根文件系统”的意思,但这里指的是内核中的一个文件系统,它和用户空间的”根文件系统”并不是一个东西initramfs:是ramfs的一个实例。initrd:我理解就是在init之前找一个临时的根文件系统进行挂载,挂载的就是initrd,比如ramdisk,initramfs
Linux Kernel 启动流程
Linux Kernel 启动的五种方式
启动方式 1
- 编译一个
init文件 - 创建一个镜像文件
disk.img,格式化为ext4文件系统,向里面写入init可执行文件(方法是挂载这个文件系统到一个目录上,把init文件丢进去,再卸载即可) - 用
qemu启动该镜像,用-hda指定硬盘镜像,--append传递命令行参数给内核(其中root=/dev/sda参数指定了根文件系统所在的块设备)
1 | qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -hda my_rootfs/root_disk/disk.img -initrd my_rootfs/old_ramdisk/ramdisk.img --append "root=/dev/sda init=/init console=ttyS0" -nographi |
但是随着时代的发展,硬件变的越来越复杂,根文件系统可能处于各种scsi,sata,flash设备上,甚至RAID阵列,可插拔的usb设备中。根文件系统还可能被压缩和加密,那么如何解压缩,如何解密则成了问题。如果根文件系统处于网络文件系统NFS中,那么内核就必须执行DHCP,DNS网络请求然后登录到目标机器中然后才能挂载根文件系统。
那么总体解决方案是不论最终的根文件系统在哪,内核先挂载一个初始根文件系统,这个初始根文件系统负责加载合适的驱动并寻找最终根文件系统并挂载。而挂载初始化根文件系统可以基于ramdisk, ramfs, tmpfs, rootfs这些技术。
启动方式 2
开启
CONFIG_BLK_DEV_RAM配置1
2
3CONFIG_BLK_DEV_RAM=y
CONFIG_BLK_DEV_RAM_COUNT=16
CONFIG_BLK_DEV_RAM_SIZE=4096用之前提到的
ramdisk技术,将其作为一个初始根文件系统挂载,创建一个镜像文件ramdisk.img,格式化成ext2文件系统后挂载,编译一个可执行文件linuxrc写入ramdisk.img,卸载该文件系统,ramdisk就创建好了- 用指定
-initrd ramdisk.img, -hda disk.img启动OS,会先执行linuxrc,再执行init
1 | qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -hda my_rootfs/root_disk/disk.img --append "root=/dev/sda init=/init console=ttyS0" -nographic |
第一种启动方式中内核执行完/init进程以后就不回头了,init进程如果退出内核会panic。
而第二种启动方式内核会利用ramdisk在上挂载ramdisk.img并执行linuxrc程序(写死的),并且等待这个程序的返回,然后内核再去挂载并执行位于/dev/sda中的init程序。linuxrc执行的任务一般是加载下一阶段init程序所需要的模块。
启动方式 3
- 编译一个
init文件 - 创建一个镜像文件
disk.img,格式化为ext2文件系统,向里面写入init可执行文件(方法是挂载这个文件系统到一个目录上,把init文件丢进去,再卸载即可) - 不指定
-hda参数,而是指定-initrd disk.img,—-append指定root=/dev/ram0
1 | qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -initrd my_rootfs/initrd/disk.img --append "root=/dev/ram0 init=/init console=ttyS0" -nographic |
这种方式只加载 disk.img 作为临时根文件系统,root=/dev/ram0指定使用ramdisk作为根文件系统,直接在ramdisk中执行init程序,不需要再切换到其他根文件系统。
启动方式 4
- 编译
init可执行文件 - 将该文件打包成
cpio格式并用gzip压缩,得到simple_initrd.cpio.gz,一个initramfs - 用
-initrd simple_initrd.cpio.gz启动initramfs,从而启动OS
上述过程无需 root 权限 ,安卓boot.img中的ramdisk启动算是此类启动方式。
1 | qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -initrd my_rootfs/initrd_cpio/simple_initrd.cpio.gz --append "init=/init console=ttyS0" -nographic |
启动方式 5
- 编译 init 可执行文件
- 将该文件打包成
cpio格式并用gzip压缩,得到simple_initrd.cpio.gz,一个initramfs - 修改内核配置
CONFIG_INITRAMFS_SOURCE="my_rootfs/initramfs/initramfs_data.cpio.gz" - 重新编译
bzImage - 直接启动OS内核,无需添加
-initrd参数
1 | qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage --append "init=/init console=ttyS0" -nographic |
linux_kernel 启动具体流程
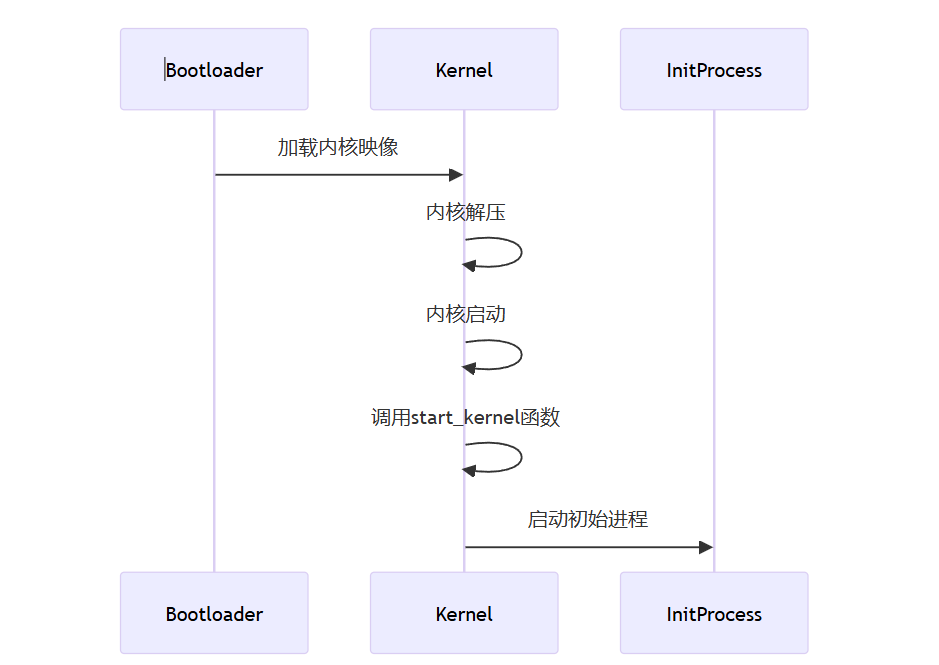
Boot Loader加载与解压缩内核镜像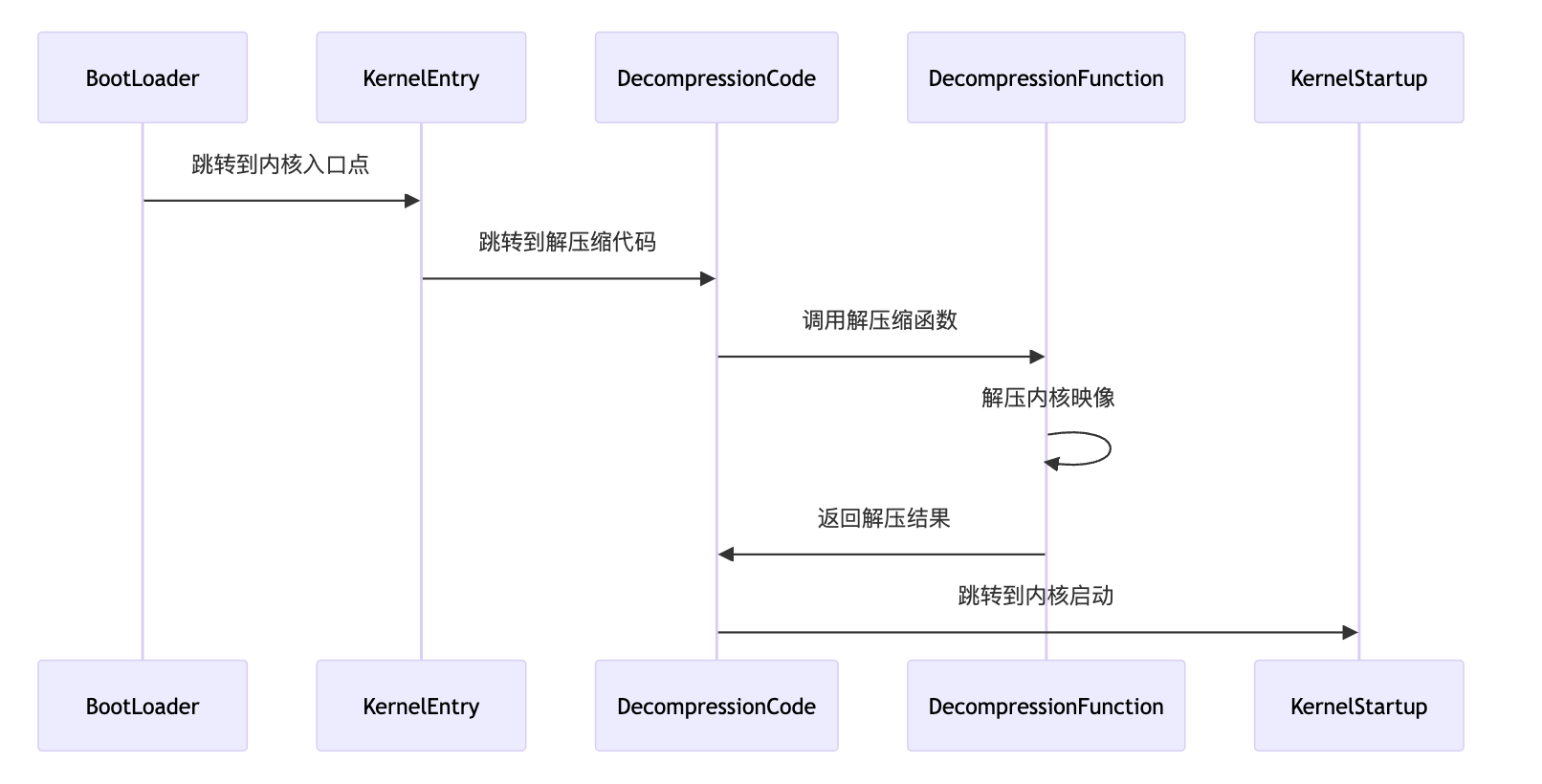
- 内核加载
- 书接上文:一般情况下,ROM中的
0xFFFFFFF0处的数据是一条跳转指令,它会将IP寄存器的值修改为0xF0000,这是BIOS的实际入口地址。这样,CPU就可以跳转到0xF0000处,开始执行BIOS的代码(在0xF0000到0xFFFFF之间,大小64K)。 - 启动扇区代码负责完成一些基本的初始化操作,然后跳转到更复杂的引导加载程序,如
GRUB的核心映像(core image,BootLoader的一部分) - 核心映像
GRUB开始执行,它负责进一步的初始化操作,如加载GRUB的模块和配置文件grub.cfg。 - 启动加载程序
GRUB根据grub.cfg文件中的配置,将压缩的内核映像(如vmlinuz)从硬盘加载到内存中。内核映像通常是一个gzip或其他格式压缩的二进制文件。 - 根据配置文件
grub.cfg,如果使用initrd(初始RAM盘)或initramfs(初始RAM文件系统),启动加载程序也会将这些文件加载到内存中,以便内核在启动时使用。 - 内核映像加载完成后,
GRUB将控制权转移给内核的入口点代码,完成控制权从BIOS到内核的转移。
GRUB、LILO、syslinux是BootLoader的具体实现。vmlinux:核心代码和数据的ELF文件。它是未经压缩和未经过处理的内核映像,通常位于内核源码目录的根目录下,包含所有内核代码、内核模块,相关数据结构,调试符号和符号表信息- 在获得编译文件
vmlinux后,通常使用压缩工具做进一步处理,将vmlinux压缩生成vmlinuz。通常使用gzip或其他压缩工具,然后再生成引导加载程序格式的内核映像,一些系统需要特定格式的内核映像,例如bzImage(适用于 x86 架构)。 vmlinuz、bzImage、zImage和uImage都是不同的 Linux 内核映像文件格式,它们各自有不同的用途和特性。在 Android 系统中,内核的压缩文件格式通常是zImage或Image.gz,具体取决于所使用的启动加载程序和设备的要求。
- 书接上文:一般情况下,ROM中的
- 内核解压缩
- 书接上文,BootLoader根据
grub.cfg文件中的配置加载内核映像(vmlinuz)到内存,并跳转到内核映像的入口点,即内核代码的起始地址。 - 内核入口点代码(在 header.S 中)会设置初始的 CPU 状态和内存环境,然后跳转到解压缩代码的入口(32位方法
startup_32,64位方法startup_64)。 - 设置解压环境,如设置段寄存器、建立临时堆栈等。
- 调用解压缩入口方法
decompress_kernel_method - 选择解压缩算法并调用相应的解压缩函数
- 解压完成后跳转到解压后到内核入口点(
arch/x86/boot/compressed/head_64.S中定义了一个跳转指令,内核入口点的地址加载到寄存器中(例如%eax),通常是内核主函数(start_kernel),跳转后即将控制权转移到解压后的内核代码)
- 书接上文:
initrd:我理解就是在init之前找一个临时的根文件系统进行挂载,挂载的就是initrd,比如ramdisk,initramfs - 加载
vmlinuz(Linux 内核映像)时,通常还会加载initrd(initial ramdisk)或initramfs(initial ram filesystem)文件,其特性如下:- 硬件驱动支持: 在系统启动时,内核可能需要加载某些
硬件驱动程序(如文件系统驱动、磁盘驱动、网络驱动等)来访问根文件系统。这些驱动程序可能并未内置在内核映像中,而是作为模块存在。initrd/initramfs提供了一个早期的文件系统,内核可以从中加载必要的模块。 - 根文件系统挂载:在一些复杂的存储配置中,如
LVM(Logical Volume Manager)、RAID、加密文件系统等,内核需要在挂载实际根文件系统之前进行一些初始化操作。这些操作通常通过initrd/initramfs中的脚本完成。 - 通用内核:发行版通常提供通用内核以支持
多种硬件配置。使用initrd/initramfs可以在启动时动态加载适配不同硬件配置的模块,而无需为每种硬件配置编译一个特定的内核。
- 硬件驱动支持: 在系统启动时,内核可能需要加载某些
- 加载过程如下:
- 启动加载程序(
BootLoader)将内核映像和initrd/initramfs文件加载到内存中,并将控制权交给内核。 - 内核启动时会识别并加载
initrd/initramfs文件,将其作为初始根文件系统挂载。 - 内核从
临时根文件系统中加载必要的模块并运行初始化脚本。 - 初始化脚本完成必要的硬件初始化和配置后,会挂载
实际的根文件系统(如/dev/sda1)。 - 初始化脚本切换到
实际根文件系统,然后移除initrd/initramfs文件。
- 启动加载程序(
- 书接上文,BootLoader根据
- 内核加载
start_kernel内核启动start_kernel 方法通常定义在 init/main.c 中,是 Linux 启动过程中的第一个 C 函数。
开始源码分析之前,先明确一些概念:
- 内核进程:内核进程是由
内核创建和调度的进程,运行在内核态,用于处理内核的各类任务。与用户进程不同,内核进程不直接与用户空间交互,主要用于执行内核内部的工作,如处理中断、管理设备、调度任务等。 - 用户进程:用户进程是在
用户空间中执行的进程,用户通过编写和执行应用程序来创建用户进程。用户进程通过系统调用与内核交互,进行资源分配、文件操作、网络通信等。 - 0号进程(
swapper/idle/空闲进程):是内核进程,运行在内核态,负责在系统空闲时执行,避免CPU闲置。在系统引导过程中,由内核初始化代码创建。 - 1号进程(
init进程):是用户进程,虽然最初由内核创建,但主要运行在用户态,负责系统初始化和管理用户空间的其他用户进程。通过kernel_init创建。 2号进程(
kthreadd进程):是内核进程,运行在内核态,负责创建和管理其他内核线程。这些内核线程通常用于执行内核中的异步任务,如磁盘I/O、网络操作等。通过kthreadd创建。源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
extern const struct kernel_param __start___param[], __stop___param[];
/* ... 其他初始化代码 ... */
/* 设置页表和内存管理 */
paging_init();
mem_init();
kmem_cache_init();
/* 设备和驱动程序初始化 */
driver_init();
init_irq_proc();
softirq_init();
time_init();
console_init();
/* 文件系统初始化 */
vfs_caches_init_early();
mnt_init();
init_rootfs();
init_mount_tree();
/* 初始化进程 */
pid_cache_init();
proc_caches_init();
/* 启动 init 进程 */
rest_init();
/* ... 其他初始化代码 ... */
/* 调用内核参数解析函数 */
kernel_param_init(karg_strings, num_args);
/* ... 其他初始化代码 ... */
/* 永远不会返回 */
cpu_idle();
}和内核启动相关的部分如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63// 内核启动入口
start_kernel()
// 初始化虚拟文件系统缓存
vfs_caches_init()
// 初始化挂载点相关的结构
mnt_init()
// 初始化根文件系统
init_rootfs()
// 判断是否配置了 TMPFS 并且 root 名称保存为空,还要检测是否指定了 tmpfs 作为根文件系统
if (IS_ENABLED(CONFIG_TMPFS) && !saved_root_name[0] && (!root_fs_names || strstr(root_fs_names, "tmpfs")))
is_tmpfs = true; // 标记使用 tmpfs 作为根文件系统
// 初始化并挂载整个根文件系统树
init_mount_tree()
// 恢复并内核挂载 rootfs 文件系统
vfs_kern_mount(&rootfs_fs_type, 0, "rootfs", NULL)
/* 初始化当前进程的工作目录和根目录,这里是 0 号进程,称为 idle 或 swapper 进程 */
set_fs_pwd(current->fs, &root);
set_fs_root(current->fs, &root);
// 调用架构相关的初始化
arch_call_rest_init()
// 执行剩余的初始化
rest_init()
// 创建 1 号进程 (init 进程),继承文件系统结构信息
kernel_thread(kernel_init, NULL, CLONE_FS)
// 初始化内核,并完成不需要硬件支持的工作
kernel_init_freeable()
// 完成基本设置
do_basic_setup()
// 执行所有初始化调用函数 (init call)
do_initcalls() -> rootfs_initcall(populate_rootfs)
// 填充根文件系统
do_populate_rootfs()
// 解压初始化 ramfs 到根文件系统
unpack_to_rootfs(__initramfs_start, __initramfs_size)
// 如果启用了 RAM 磁盘设备,填充 INITRD 镜像
populate_initrd_image(err);
// 当根文件系统就绪后控制台初始化
console_on_rootfs()
// 如果不能访问指定的启动命令,准备 namespace
if (init_eaccess(ramdisk_execute_command) != 0)
prepare_namespace()
// 加载临时 root disk 镜像
initrd_load()
// 挂载根文件系统
mount_root()
/* 创建设备节点 /dev/root, 并挂载到 ROOT_DEV 指定位置 */
create_dev("/dev/root", ROOT_DEV)
// 使用块设备文件系统挂载根
mount_block_root("/dev/root", root_mountflags)
// 挂载设备文件系统
devtmpfs_mount();
// 将初始化挂载点移动到新挂载位置
init_mount(".", "/", NULL, MS_MOVE, NULL);
// 更改根目录以符合 chroot 规范
init_chroot(".");
// 尝试运行初始化进程
try_to_run_init_process()
不论哪种启动方式,都会走到
init_mount_tree()函数,调用vfs_kern_mount,并执行set_fs_pwd, set_fs_root,这里current是0号进程idle。我们之前提到,不管哪种启动方式,都需要有一个临时的根文件系统,可以是ramfs也可以是tmpfs0号进程(
idle进程)是在系统引导过程中,由内核初始化代码创建的。在x86架构中,这个过程发生在汇编启动代码(通常在arch/x86/kernel/head.S中),该代码会设置基本的CPU和内存环境,然后跳转到C语言的start_kernel函数。1
2
3
4
5
6
7// 初始化并挂载整个根文件系统树
init_mount_tree()
// 恢复并内核挂载 rootfs 文件系统
vfs_kern_mount(&rootfs_fs_type, 0, "rootfs", NULL)
/* 初始化当前进程的工作目录和根目录,这里是 0 号进程,称为 idle 或 swapper 进程 */
set_fs_pwd(current->fs, &root);
set_fs_root(current->fs, &root);接下来会在
rest_init函数中调用kernel_thread(kernel_init, NULL, CLONE_FS)创建1号进程,并继承挂载的rootfs文件系统信息。然后
do_basic_setup初始化驱动,调用populate_rootfs函数,该函数会调用unpack_to_rootfs(__initramfs_start, __initramfs_size)将initramfs的内容解压至rootfs1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 调用架构相关的初始化
arch_call_rest_init()
// 执行剩余的初始化
rest_init()
// 创建 1 号进程 (init 进程),继承文件系统结构信息
kernel_thread(kernel_init, NULL, CLONE_FS)
// 初始化内核,并完成不需要硬件支持的工作
kernel_init_freeable()
// 完成基本设置
do_basic_setup()
// 执行所有初始化调用函数 (init call)
do_initcalls() -> rootfs_initcall(populate_rootfs)
// 填充根文件系统
do_populate_rootfs()
// 解压初始化 ramfs 到根文件系统
unpack_to_rootfs(__initramfs_start, __initramfs_size)
// 如果启用了 RAM 磁盘设备,填充 INITRD 镜像
populate_initrd_image(err);五种启动方式到目前为止的流程基本一致,总结下就是挂载一个
临时根文件系统,创建1号进程,执行驱动初始化,如果initramfs符合对应的格式,就将里面的内容解压至rootfs,而后续的操作对不同的启动方式略有不同。启动方式 1
1
qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -hda my_rootfs/root_disk/disk.img --append "root=/dev/sda init=/init console=ttyS0" -nographic
由于
initramfs是空的,也没有指定initrd选项,看一下do_populate_rootfs函数的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static void __init do_populate_rootfs(void *unused, async_cookie_t cookie)
{
char *err = unpack_to_rootfs(__initramfs_start, __initramfs_size);
if (!initrd_start || IS_ENABLED(CONFIG_INITRAMFS_FORCE))
goto done;
err = unpack_to_rootfs((char *)initrd_start, initrd_end - initrd_start);
if (err) {
populate_initrd_image(err);
printk(KERN_EMERG "Initramfs unpacking failed: %s\n", err);
}
done:
if (!do_retain_initrd && initrd_start && !kexec_free_initrd())
free_initrd_mem(initrd_start, initrd_end);
initrd_start = 0;
initrd_end = 0;
}initrd_start显然就是0了,直接进入done标签返回到kernel_init_freeable函数,且initrd_start=init_end=0,而如果没有设置内核命令行参数"rdinit=",ramdisk_execute_command初始化为/init,init_eaccess(ramdisk_execute_command) != 0这个条件会检查ramdisk_execute_command这个文件是否存在,由于我们没有在rootfs中添加init,所以条件不为0,进入prepare_namespace函数。1
2if (init_eaccess(ramdisk_execute_command) != 0)
prepare_namespace()然后看一下
prepare_namespace函数在干嘛。root_device_name是/dev/sda,后面root_device_name+=5相当于把/dev/前缀删掉,进入initrd_load函数,initrd_load函数会使用create_dev("/dev/ram", Root_RAM0)函数创建一个/dev/ram设备节点,映射到RAM0设备,然后尝试加载initrd镜像,由于方式一没有initrd.image,所以没有选择加载。然后会回到
prepare_namespace函数,由于我们指定了root=/dev/sda,会执行mount_root, init_mout, init_chroot,先将ROOT_DEV,也就是sda挂载到/dev/root,然后调用init_mount将当前工作目录(`/root)移动挂载至**/**目录下,再调用init_chroot切换当前进程的根目录至当前目录。而我们之前编译的init可执行文件就会被写入这个目录中,根文件系统挂载完毕以后就可以调用run_init_process(“/init”)执行根文件系统上的init程序了,1号进程就切换到了用户空间`去执行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36void __init prepare_namespace(void)
{
wait_for_device_probe();
md_run_setup();
if (saved_root_name[0]) {
root_device_name = saved_root_name;
if (!strncmp(root_device_name, "mtd", 3) ||
!strncmp(root_device_name, "ubi", 3)) {
mount_block_root(root_device_name, root_mountflags);
goto out;
}
ROOT_DEV = name_to_dev_t(root_device_name);
if (strncmp(root_device_name, "/dev/", 5) == 0)
root_device_name += 5;
}
if (initrd_load())
goto out;
if ((ROOT_DEV == 0) && root_wait) {
printk(KERN_INFO "Waiting for root device %s...\n",
saved_root_name);
while (driver_probe_done() != 0 ||
(ROOT_DEV = name_to_dev_t(saved_root_name)) == 0)
msleep(5);
async_synchronize_full();
}
mount_root();
out:
devtmpfs_mount();
init_mount(".", "/", NULL, MS_MOVE, NULL);
init_chroot(".");
}这种方式是
rootfs→sda启动方式 2
1
qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -hda my_rootfs/root_disk/disk.img -initrd my_rootfs/old_ramdisk/ramdisk.img --append "root=/dev/sda init=/init console=ttyS0" -nographic
由于指定了
-initrd参数,所以会执行unpack_to_rootfs函数将ramdisk.img的内容解压进rootfs,但是由于其不是cpio格式,而是ext2格式,所以报错"rootfs image is not initramfs (invalid magic at start of compressed archive); looks like an initrd",并进入到populate_initrd_image()函数。populate_initrd_image会在rootfs中创建initrd.image,并将-initrd选项指定的ramdisk.img内容写入/initrd.image文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static void __init populate_initrd_image(char *err)
{
ssize_t written;
struct file *file;
loff_t pos = 0;
unpack_to_rootfs(__initramfs_start, __initramfs_size);
file = filp_open("/initrd.image", O_WRONLY|O_CREAT|O_LARGEFILE, 0700);
if (IS_ERR(file))
return;
written = xwrite(file, (char *)initrd_start, initrd_end - initrd_start,
&pos);
if (written != initrd_end - initrd_start)
fput(file);
}由于此时根文件系统仍然没有
ramdisk_execute_command文件存在,所以依然会进入prepare_namespace函数,但是这次有了/initrd.image文件,进入到下面这个逻辑1
2
3
4
5if (rd_load_image("/initrd.image") && ROOT_DEV != Root_RAM0) {
init_unlink("/initrd.image");
handle_initrd();
return true;
}rd_load_image的逻辑是先尝试识别出/initrd.image文件的格式,由于ramdisk.img的格式是ext2,因此会打印出"RAMDISK: ext2 filesystem found at block 0"表示识别出是ext2的文件格式。接下来将/initrd.image文件拷贝至ramdisk设备文件/dev/ram中。由于这种启动方式
ROOT_DEV为/dev/sda,ROOT_DEV != Root_RAM0判断就为True,看一下handle_initrd函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52static void __init handle_initrd(void)
{
struct subprocess_info *info;
static char *argv[] = { "linuxrc", NULL, };
extern char *envp_init[];
int error;
// 先创建设备节点/dev/root.old,然后将initrd挂载到rootfs的/root目录,并在根文件系统下创建和切换到/old目录。
real_root_dev = new_encode_dev(ROOT_DEV);
create_dev("/dev/root.old", Root_RAM0);
mount_block_root("/dev/root.old", root_mountflags & ~MS_RDONLY);
init_mkdir("/old", 0700);
init_chdir("/old");
current->flags |= PF_FREEZER_SKIP;
// 使用call_usermodehelper_setup设置用户模式帮助程序linuxrc,并调用call_usermodehelper_exec执行。
info = call_usermodehelper_setup("/linuxrc", argv, envp_init,
GFP_KERNEL, init_linuxrc, NULL, NULL);
if (!info)
return;
call_usermodehelper_exec(info, UMH_WAIT_PROC);
current->flags &= ~PF_FREEZER_SKIP;
// 将initrd移动到rootfs的/old目录,并切换回根文件系统的根目录。
init_mount("..", ".", NULL, MS_MOVE, NULL);
init_chroot("..");
// 如果解码的真实根设备为Root_RAM0,则返回。
if (new_decode_dev(real_root_dev) == Root_RAM0) {
init_chdir("/old");
return;
}
// 否则,尝试将旧根文件系统移动到/root/initrd,再调用mount_root继续dev/sda挂载
init_chdir("/");
ROOT_DEV = new_decode_dev(real_root_dev);
mount_root();
printk(KERN_NOTICE "Trying to move old root to /initrd ... ");
error = init_mount("/old", "/root/initrd", NULL, MS_MOVE, NULL);
if (!error)
printk("okay\n");
else {
if (error == -ENOENT)
printk("/initrd does not exist. Ignored.\n");
else
printk("failed\n");
printk(KERN_NOTICE "Unmounting old root\n");
init_umount("/old", MNT_DETACH);
}
}最后回到
prepare_namespace,挂载sda后返回,执行run_init_process("/init")函数启动位于sda设备上的init进程。这种启动方式是
rootfs→ramdisk initrd→sda启动方式 3
1
qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -initrd my_rootfs/initrd/disk.img --append "root=/dev/ram0 init=/init console=ttyS0" -nographic
和启动方式2的区别就是
root=/dev/ram0指定的最终根文件系统是/dev/ram01
2
3
4
5if (rd_load_image("/initrd.image") && ROOT_DEV != Root_RAM0) {
init_unlink("/initrd.image");
handle_initrd();
return true;
}执行这个判断的时候就不会进入
handle_initrd函数,而是将ram0直接挂载到根文件系统执行上面的init文件这种方式也是
ramdisk到一种应用,是rootfs→ram0启动方式 4
1
qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage -initrd my_rootfs/initrd_cpio/simple_initrd.cpio.gz --append "init=/init console=ttyS0" -nographic
指定了
-initrd参数,且格式是cpio格式,那么在do_populate_rootfs函数执行unpack_to_rootfs解压时会成功,将-initrd选项指定的simple_initrd.cpio.gz内容解压至rootfs,且不会进入与ramdisk相关的populate_initrd_image函数,而是调用free_initrd_mem将initrd的物理内存释放掉。此时
rootfs也有了/init文件,所以init_eaccess(ramdisk_execute_command) !**=** 0这个条件不成立,也不会进入prepare_namespace函数,而是直接run_init_process("/init")执行init程序。cpio的格式非常简单,内核的解压代码也非常少。这种启动方式虽然也叫initrd,但是用的是cpio格式的initrd,和上面ramdisk格式的initrd区别很大,为主流的启动方式,init进程启动以后可以再执行额外查找并挂载文件系统的操作,只不过这些都是用户空间的事了。这种方式是
rootfs→cpio initrd启动方式 5
1
qemu-system-x86_64 -kernel arch/x86_64/boot/bzImage --append "init=/init console=ttyS0" -nographic
和启动方式4差不多,只是把cpio压缩包和内核编译在了一起。
由于添加了配置项,在
do_populate_rootfs函数1
2
3
4
5
6
7/* Load the built in initramfs */
char *err = unpack_to_rootfs(__initramfs_start, __initramfs_size);
if (err)
panic_show_mem("%s", err); /* Failed to decompress INTERNAL initramfs */
if (!initrd_start || IS_ENABLED(CONFIG_INITRAMFS_FORCE))
goto done;这部分执行完以后,就直接去了
done标签返回。这种方式是
rootfs->initramfs总结
启动方式1直接把sda设备指定为最终的rootfs启动init进程,局限性较高。启动方式2利用ramdisk initrd在挂载最终的rootfs之前,会在ramdisk initrd中执行linuxrc程序进行预处理,加载init进程需要的环境,但是这种方式已被弃用。启动方式3也是利用ramdisk技术,将init直接写入ram0中,并把dev/ram0作为最终的rootfs。启动方式4使用cpio格式的initrd,直接将文件系统解压到内存中,运行init进程,然后再在用户态执行后续的挂载等操作。启动方式5把cpio-gzip文件和内核编译到一起,在initramfs直接启动init进程。综上所述这五种启动方式都会有可用的
rootfs,initrd分为ramdisk initrd和cpio initrd,安卓文档中甚至把initrd也叫做initramfs,因此initrd并不单单指的是ramdisk技术,android boot.img中解压出来的ramdisk文件本质上cpio格式,用的并不是ramdisk initrd技术而是cpio initrd。这些名词概念极容易产生误导,理解了上面启动的代码流程才是最重要的。
- 内核进程:内核进程是由
init进程引导系统加载启动init进程启动后,通过后续工作完成了操作系统的加载和启动。
- init进程读取
系统的初始化脚本(如/etc/inittab, /etc/init.d/脚本)或systemd的单元文件(unit files),执行系统初始化任务。这包括设置系统环境、挂载文件系统、启动网络服务、启动守护进程等。 - 如果系统配置为使用图形界面,
init进程会启动图形登录管理器(如GDM、LightDM、SDDM)。这些登录管理器负责提供图形化的登录界面,供用户输入用户名和密码。用户登录成功后,登录管理器会启动用户的桌面环境(如GNOME、KDE、Xfce)。桌面环境提供完整的图形用户界面,允许用户运行应用程序、管理文件、设置系统等。 systemd作为init进程启动,读取其配置文件(通常在/lib/systemd/system/和/etc/systemd/system/),然后根据配置文件启动系统目标(如graphical.target),启动图形显示管理服务,显示管理器提供用户登录界面,用户登录后启动用户会话,显示管理器启动桌面环境,用户进入图形用户界面。
- init进程读取
参考文档
 wechat
wechat

